Google Agent Development Kit (ADK)

If you read my last post about Google's File Search tool, you know I love finding the "gotchas" in shiny new API documentation. So, naturally, I decided to poke the bear again.
This time, I tackled the Agent Development Kit (ADK). The promise? A unified, code-first framework to build AI agents that can research, reason, and create content. Think of it as "LangChain, but Google-flavoured."
I spent the weekend building a content research bot, among other multi-agent systems. And look, when it works, it’s brilliant. It feels robust, "enterprise-y", and very serious. But if you are planning to use this in production, especially if you aren't a Python developer, you need to sit down for this.
Here are the shortfalls I discovered while wrestling with the ADK.
1) Typescript Users: Please Use the Service Entrance
In the Python version of ADK, switching models is a breeze. Want to use OpenAI’s GPT-4o instead of Gemini? No problem! You just import LiteLLM, swap a line of code, and you’re off to the races.
In TypeScript? Good luck.
While Google says the ADK is model-agnostic, the TypeScript libraries are surprisingly rigid. Out of the box, they are hard-wired for Google’s Vertex AI and Gemini models. If you want to use a non-Google model (like Claude or GPT models) in TypeScript, you aren't just changing a config setting; you are likely writing your own custom wrapper or "Model Client" from scratch.
It feels like showing up to a "Bring Your Own Beer" party, only to be told that "Beer" is defined exclusively as Guinness.
2) Bring Your Own Database
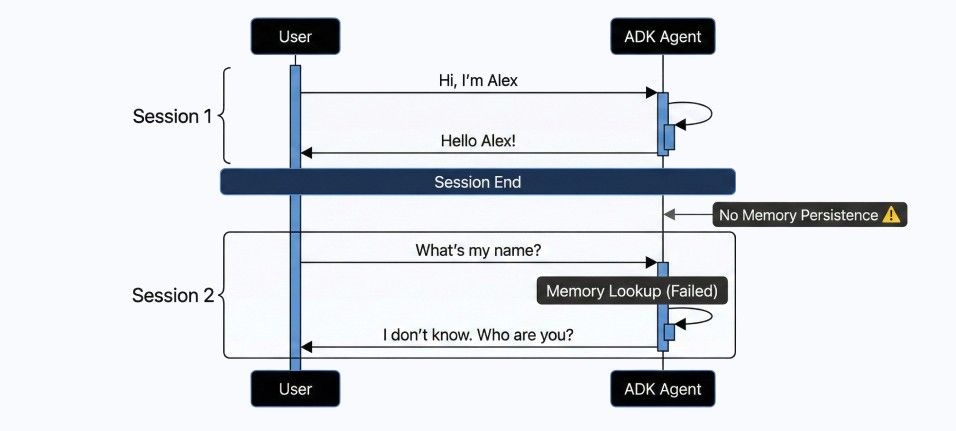
Much like the File Search tool, the ADK has a weird relationship with memory.
By default, the agents are shockingly forgetful. The "Runner" (the engine that drives the agent) is often ephemeral. If you are building a demo, this is fine. But if you want your agent to remember a conversation from yesterday, you can't just flip a "memory=true" switch.
You have to implement your own persistence layer. You need to spin up a database (Firestore, PostgreSQL, etc.), write a custom implementation of their Session interface, and wire it all up yourself. Other frameworks handle this with a simple localised database file for testing; ADK demands an enterprise architecture diagram just to remember your name.
3) The "Rigid Folder" Dictatorship
Most libraries let you organise your code however you want. ADK has... opinions.
It expects a very specific folder structure for your agents, tools, and configurations. If you name a file my_cool_tool.ts instead of my_cool_tool.tool.ts (or whatever specific convention the version demands), the framework simply won't see it. No error message, no crash, just silent ignoring. You’ll spend hours debugging logic only to realise your file name was missing a suffix.
4) Dependency Hell
If you are using the TypeScript SDK in a modern web framework (like Next, Nuxt or Remix), prepare for a battle.
The ADK library seems to be built with a "backend-only, Node.js-pure" mindset. When you try to bundle it for certain environments, you might hit errors about missing lodash-es exports or weird CommonJS vs. ESM module conflicts.
The Verdict?
Google’s ADK is a powerhouse if you are:
- Using Python.
- Hosting on Google Cloud Platform.
- Using Gemini models.
If you fit that profile, it’s amazing. If you don’t, especially if you are a TypeScript developer wanting to orchestrate OpenAI models, you are going to feel like you’re fighting the framework every step of the way.
My advice? Use it for the "Google Native" stuff. For everything else, you might want to wait for the TypeScript support to grow up a little bit.