Retrieval-Augmented Generation

Why does it exist?
I've been wanting to share my thoughts about RAG for a while and I've finally got around to it. The premise behind the framework seems so obvious yet it is widely misunderstood, and it's impact severely under appreciated. So I thought to myself, the best way to truly grasp the framework instead of regurgitating existing attempts at explaining RAG would be to build a retrieval-augmented generation system myself and really get under the hood.
Before we understand the how, we must explore the why? There are four primary limitations of generative AI:
1) Hallucinations
One of the first drawbacks you've probably heard of, this is where an LLM will very confidently reply to your query or prompt with a response that sounds plausible and very convincing, but is not factually correct or is fabricated entirely.
2) Knowledge Cut-offs
Generative AI applications that do not have access to real-time search functionalities suffer from knowledge restrictions brought about by pre-training cut off dates. If you require information that is very recent or time-specific, past an LLM's knowledge cut off you might as well resort to asking Clippy for help.
3) Limited Context Windows
Large language models have finite context windows, amongst commercially available models Google Gemini's 1.5 Pro has the largest context window at the time of writing this article, boasting a context length of up to 2 million tokens. That's approximately 3000 single-spaced A4 pages of text with a 12pt font size, using Times New Roman. Can you maintain the context of a 3000 page document? As impressive as this is, for longer-form content or conversations due to the finite nature of these context windows, eventually these models slow down and the accuracy of their responses start to decay.
4) Cost Implications
If you need to generate high-quality text, images or videos, especially for longer-form content in high volumes, this often requires the latest and greatest AI models available and their API costs are not cheap.
RAG aims to combat some of these limitations, especially hallucinations and knowledge cut-offs by providing a real-time search layer that can ground an LLM's response in a verifiable source, allowing for more reliable responses.
I'll explain why this is necessary with an anecdote. A few weeks ago I managed to pry my mates from their new born babies to decompress over a nice dinner where we reminisced about old times and chatted about our about travels. Not too long into the conversation one of my friend's asked "I wonder how many official countries there are in the world?". I leapt at this, "Ooh, I read an article about this, there's about 185 official countries in the world!". Sounds plausible and so he accepted this as fact. However, there were two things wrong with my answer (in addition to my answer being wrong entirely):
- I had no credible source to substantiate my answer.
- I haven't been keeping up with the official country count since I last read the article a few years ago.
Now what would have happened if I looked up the answer to this question via a credible source such as Worldometer? Well, I would be able to respond with an answer that was a lot more believable - "There are 195 official countries as of 2025", grounding my answer in something a lot more believable and factual. This is exactly what RAG aims to solve.
So, how does RAG actually keep me from spouting another “185 countries” whopper? Here is the short version you can tell your friends. RAG bolts a real-time retrieval layer onto a language model. Instead of trusting whatever the model thinks it remembers, we fetch supporting passages from a knowledge base, feed those into the prompt, then ask the model to answer using those sources. That single idea grounds the model and cuts hallucinations because the response is built on verifiable text, not vibes. If you want a crisp definition to wave around, IBM’s research team sums it up neatly. RAG improves answer quality by grounding an LLM on external sources.
The RAG pipeline in plain English
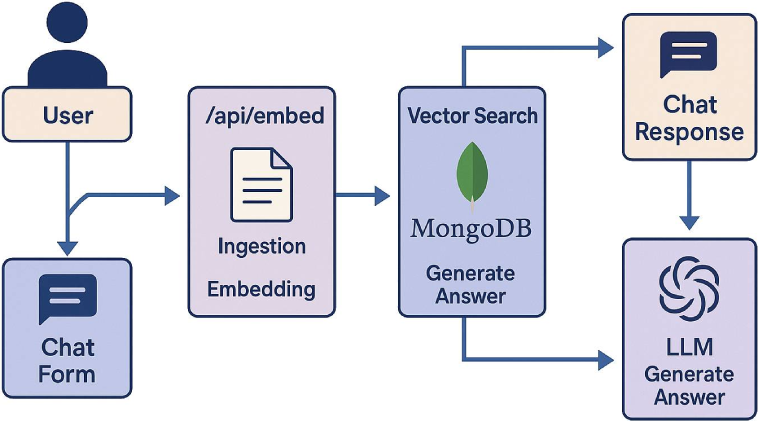
1) Ingest and slice
When I upload a document, the server extracts the text and splits it into bite-sized chunks of around 500 words. The exact size is a tuning knob, but the goal is simple. Big enough for context. Small enough to be searchable and cheap.
2) Vectorise with embeddings
Each chunk is turned into a dense vector using the OpenAI Embeddings API. Today the recommended workhorse is text-embedding-3-small or text-embedding-3-large, with dimensionality and pricing documented in OpenAI’s guide and pricing page. These vectors are just numbers, but nearby vectors mean similar meaning, which is exactly what we need for semantic search.
3) Store and index
I store the chunk text, metadata and the vector in MongoDB Atlas, then build a Vector Search index so I can query by similarity at speed. Atlas also supports hybrid patterns, so I can combine vector search with classic text search when I need exact keywords. That is handy when a user remembers the phrase “accrual method” and nothing else.
4) Embed the question
When a user asks a question, I embed the question with the same OpenAI embeddings model. Symmetry matters here. You want the query vector to live in the same geometric space as your document vectors, otherwise distance means nothing.
5) Retrieve the good stuff
I run a vector search to pull the most semantically similar chunks, and I often run a text search alongside it for exact matches, then merge and deduplicate. This hybrid retrieval pattern gives you the best of both worlds. Semantic recall without losing literal matches.
6) Build a grounded prompt
Each selected chunk is labelled as “Source 1”, “Source 2” and so on, then stuffed into the context with the user’s question. The prompt tells the model to quote directly when appropriate and to show [Source N] next to any quote. This keeps the model honest and gives the reader a breadcrumb trail to the original paragraph. The idea of combining parametric memory with a non-parametric index is exactly what the original RAG work described, although my stack is very much the 2025 flavour.
7) Generate the answer
I send that prompt to an LLM. Gemini 2.0 Flash is a great fit because it is fast and handles large contexts. Google’s documentation lists long context capabilities and details for current models, including 1M token windows in the Flash family and separate guidance on working with million-token contexts. That buys you headroom when your sources are chunky.
8) Show citations that actually match
After the model replies, I parse out any “quoted text” [Source N] from the answer. For each quote I slice the original chunk with a small padding window, so the citation card shows the exact sentence the model used plus a little context. It is boring engineering and it works.
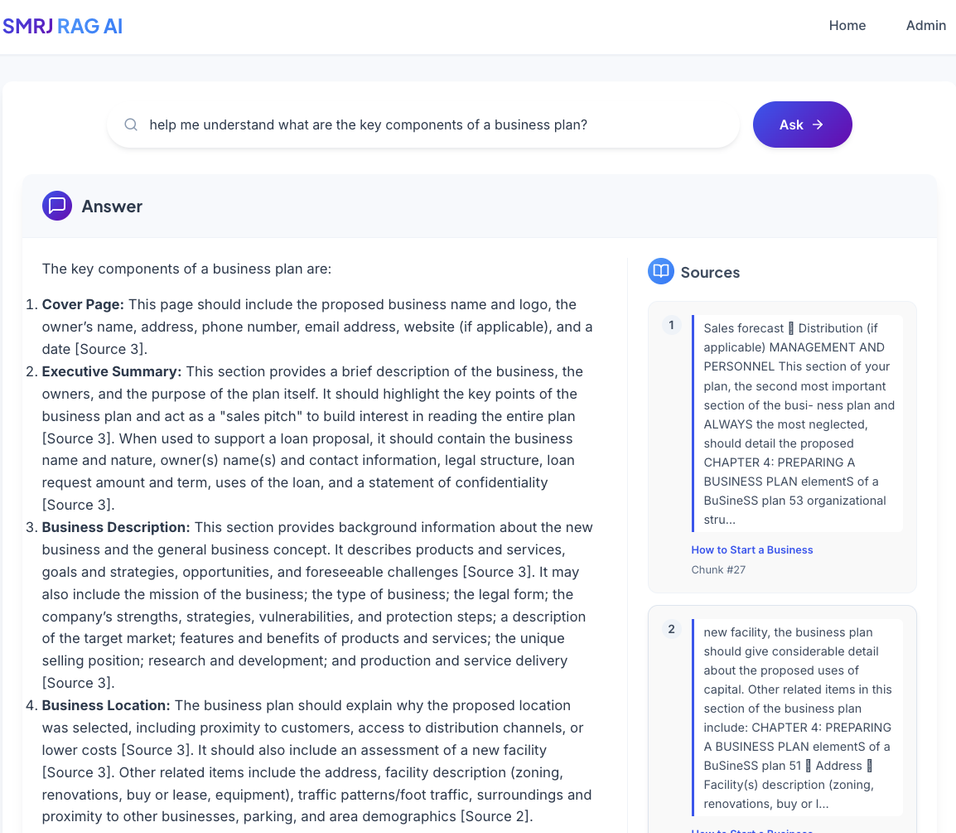
What RAG fixes from the list above
- Hallucinations The model is encouraged to copy from retrieved passages and to cite them. You still need good retrieval, but the path to a grounded answer is now paved with sources rather than guesswork.
- Knowledge cut-offs The LLM can answer with yesterday’s policy doc or this morning’s release notes because you retrieve from your own store, not the model’s pretraining snapshot. AWS’s overview frames it as optimising an LLM so it references an authoritative knowledge base before it speaks. That is the point.
- Context windows and cost Instead of cramming the entire archive into the prompt, you pass only the best few chunks. That keeps token usage and latency sane while still giving the model the right facts. For very long prompts, the Gemini docs on long context are a good playbook for staying efficient.
Real-world RAG use cases
1) Customer support & product help
Ground chatbots on manuals, policy docs, and known issues so they answer with up-to-date, source-linked guidance instead of inventing fixes.
2) Internal knowledge search for employees
Let staff query wikis, SharePoint, and confluence-style portals and get answers with citations, not just a list of links. Managed services like Bedrock Knowledge Bases show this end-to-end pattern.
3) Compliance & policy Q&A
In regulated environments, you must show why an answer is allowed. RAG provides traceable citations to the exact clause or control that justified the answer. Azure and AWS guidance both frame RAG as a design pattern for this.
4) Healthcare & life sciences operations
Ground responses on clinical guidelines, formulary docs, or payer policies to reduce risky hallucinations in operational workflows (prior auth, coverage rules, etc.).
5) Financial & research workflows
Pull from filings, earnings call transcripts, and internal memos to draft summaries and answer questions with citations your analysts can audit.
Variants you will hear about
CAG, Cache-Augmented Generation
CAG leans into today’s giant context windows. Rather than retrieving on each question, you preload a curated knowledge set into the context and reuse a key-value cache, cutting retrieval overhead. It shines when your knowledge base is relatively stable and can fit into the model’s long context. The through-line is the same. If your knowledge fits in memory, caching can be faster and simpler. If your knowledge is large or frequently updated, RAG still wins.
Agentic RAG
Instead of one retriever, you have a small team of specialised agents. One searches your vector store, another queries a SQL warehouse, another hits web search. An aggregator agent then reconciles everything and builds the grounded context for the final model. In practice it lets you scale both breadth and reliability, especially for complex, multi-hop questions.
| Dimension | RAG | CAG | Agentic RAG |
|---|---|---|---|
| High-level idea | Retrieve top-k relevant chunks, pass them to the LLM as context, generate an answer with citations | Keep retrieval but add stricter, chunk-aware controls such as reranking, citation scoring and refusal when evidence is weak | Use multiple specialised agents to fetch from many sources, then an aggregator agent builds a grounded context for the final LLM |
| Retrieval | Vector search, often with optional keyword search | Vector plus keyword hybrid, rerankers and filters tuned per chunk | Many retrievers. Web, APIs, SQL, vector stores, file systems, tools |
| Context build | Concatenate selected chunks with “Source N” markers | Evidence pack with per-chunk metadata, deduping, stricter limits | Aggregator merges agent outputs, resolves conflicts, builds final pack |
| LLM role | Single model answers, encouraged to quote and cite | Single model answers but is steered to respect evidence boundaries | Planner, retriever and aggregator may be separate models or roles; final answerer composes the response |
| Strengths | Simple, fast, cheap, easy to ship. Clear citations | Fewer hallucinations, better faithfulness, more controllable | Broadest coverage, can do multi-step and multi-source tasks, resilient |
| Weaknesses | Quality depends on retrieval; can include off-topic chunks | Slightly higher latency and complexity to tune | Highest complexity, higher latency and cost, orchestration required |
| When it shines | Q&A over handbooks, policies, product docs, knowledge bases | Compliance, legal, medical or any setting where citations must be strict | Research, enterprise analytics, incidents, decisions that span many systems |
| Latency | Low | Medium | Medium to high |
| Cost | Low | Low to medium | Medium to high |
| Engineering effort | Low | Medium | High |
| Governance and audit | Basic citations | Stronger grounding and refusal behaviour | Best for audit trails if you log agent traces and decisions |
| Typical failure mode | Irrelevant top-k retrieval leads to weak answers | Over-strict filters may refuse or miss useful context | Tool misfires, agent disagreement, orchestration bugs |
| Example add-ons | Reranker, query expansion, hybrid search | Evidence scoring, entailment checks, “answer only if supported” gates | Planner agent, de-duplication, cross-source conflict resolution |
When to reach for what
- Pick standard RAG if your corpus is big, changes often, or must be traceable with citations.
- Pick CAG if your corpus is stable and fits into a long context, and you care about speed and simplicity.
- Consider Agentic RAG when your answers depend on multiple systems and you want redundancy in retrieval.
That is the whole story. RAG exists because we want models that are helpful and right, not just confident. By embedding both your documents and your questions, retrieving the most relevant slices with a vector index, and then asking the model to answer from those slices, you can answer with receipts.